Python/Scikit-learnでk近傍法で時系列データの異常部位検出する方法について紹介します。
【応用例】時系列データの異常検知
次のようなサンプル数Nの時系列データXが与えられているとします。
(1) 
ここで、k近傍法に適用するために、時系列データを適当な窓幅(WN)を指定し、窓内の点を並べて1つのベクトルにします。
最後にそのベクトルを集合にします。
にする必要があります。
(2) 
こうして作られたベクトルWをk近傍法で用います。
【Scikit-learn】時系列データの異常検知(k近傍法)
k近傍法とは、学習データをベクトル空間上にプロットし、未知データ(入力データ)と学習データの距離が近い順に任意のK個を取得し、多数決でデータが属するクラスを推定するです。
比較的シンプルなアルゴリズムですが、時系列データの異常検知にも活用できます。
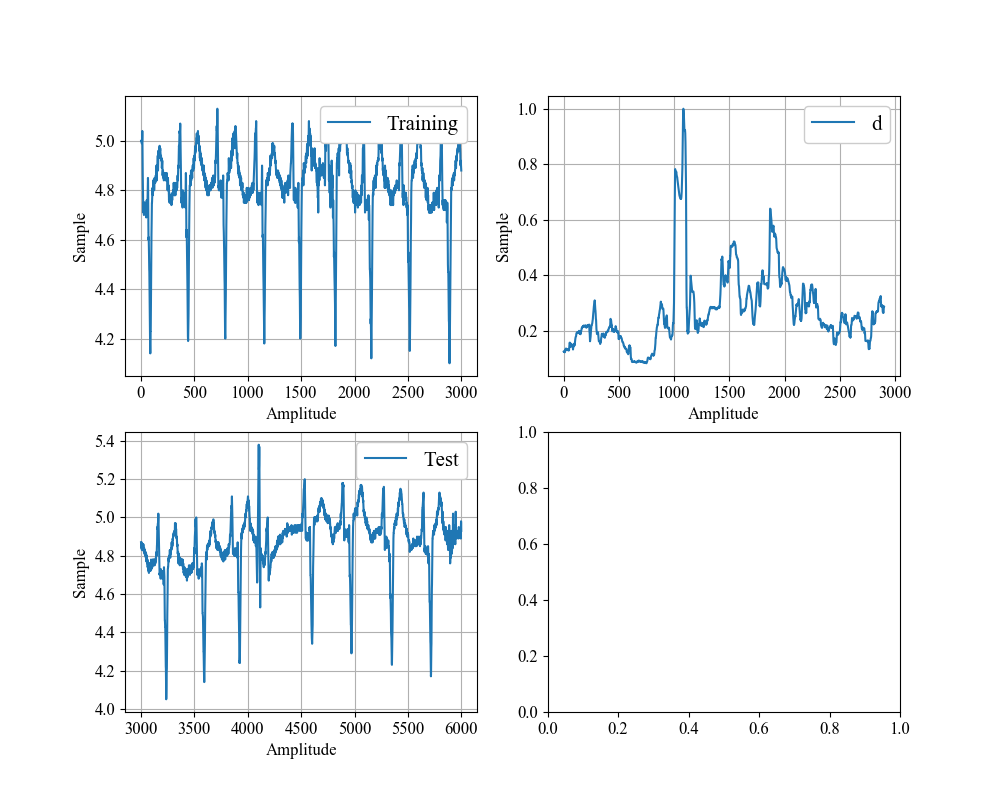
今回は心電図データセット(http://www.cs.ucr.edu/~eamonn/discords/)を使っています。
異常を含む区間で異常度が高くなりました。
綺麗な周期データが予測される場合には有効ですが、周期データでも徐々に上昇していくような場合は良い結果が得られません。

【機械学習】時系列データの異常検出手法
機械学習や深層学習を用いた時系列データの異常検出手法についてまとめました。
algorithm.joho.info
2020.02.09
コメント