Pythonモジュール「scikit-learn」でL2正則化により過学習を改善しながらロジスティック回帰分析する方法についてまとめました。
【1】ロジスティック回帰とは
ロジスティック回帰とは、説明変数が定量データ、目的変数が2値(あり、なしなど)をとる多変量解析の1つです。
線形回帰を応用(線形回帰の出力をロジット関数に入力)したもので、2分類問題(2値の目的変数をもつ問題)に対して利用します。
2分類問題数とは、例えば「生存・死亡」や「陽性・陰性」を判別するといったものです。
今回はロジスティック回帰をPython用機械学習ライブラリ「scikit-learn」で実装してみます。
動画解説
サンプルコード
サンプルプログラムのソースコードです。
input.csv
test.csv
以下のようなルールのデータです。
x1とx2の和が10以上・・・x3は1
x1とx2の和が10未満・・・x3は0
検証結果は、4つともそのように判別していることがわかります。

【2】データセット(アヤメの品種)の取得
過学習対策について学ぶ前に、load_iris()でアヤメの品種判別のデータセットを取得します。
データセットの中身は次のとおり。
| 種別 | 概要 |
|---|---|
| 説明変数 | 4つの値(がく片の長さ、がく片の幅、花弁の長さ、花弁の幅)。単位はいずれもcm。 |
| 目的変数 | アヤメの品種(3種類:setosa、versicolor、virginicaを0、1、2の数値ラベル化) |
【3】データ特性の検証(散布図、ヒストグラム、ヒートマップ)
データセット(説明変数、目的変数)の特性を散布図、ヒストグラム、ヒートマップなどで観察してみます。
散布図
※各品種に対して、順に50セットのデータがデータセットに格納されています。
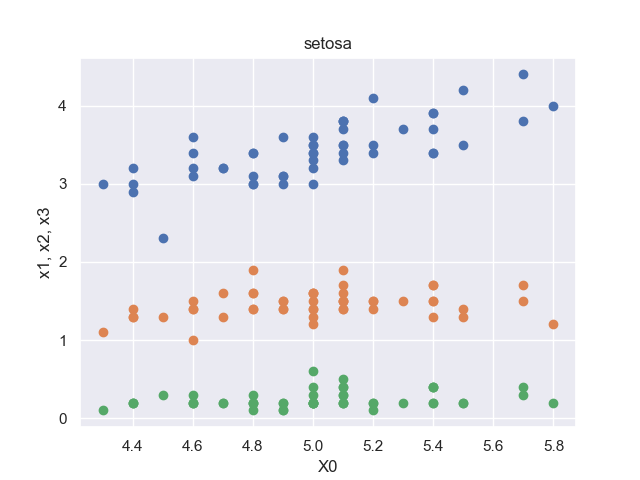
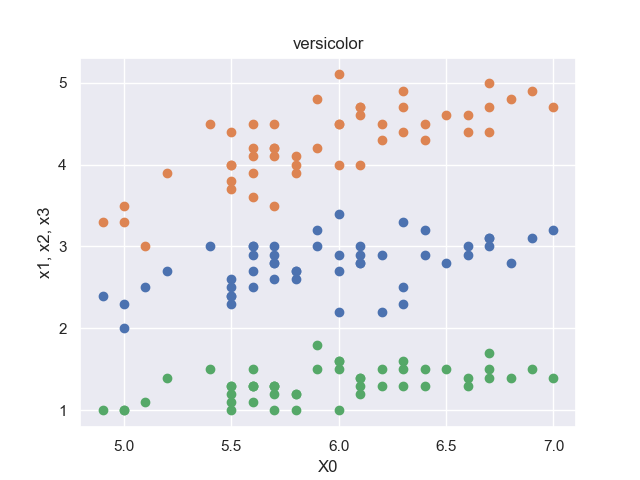
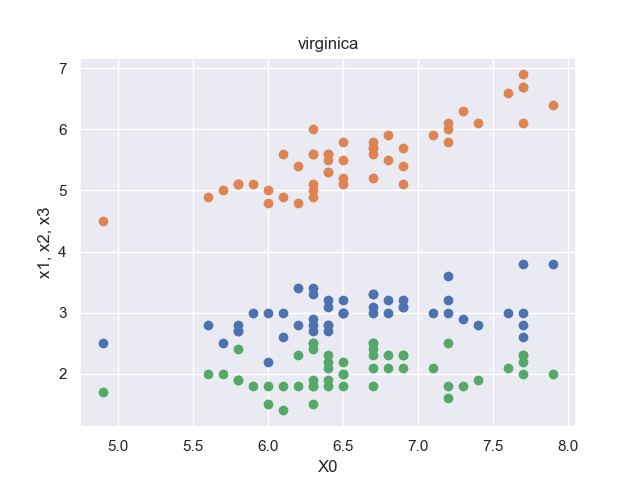
setosaの散布図のみ、オレンジの点群(がく片の長さ, 花弁の長さ)が真ん中に来ています。
よって、アヤメの品種が「setosa」か「setosa以外か」という判定は行いやすいだろうと推察できます。
ヒストグラム
相関ヒートマップ
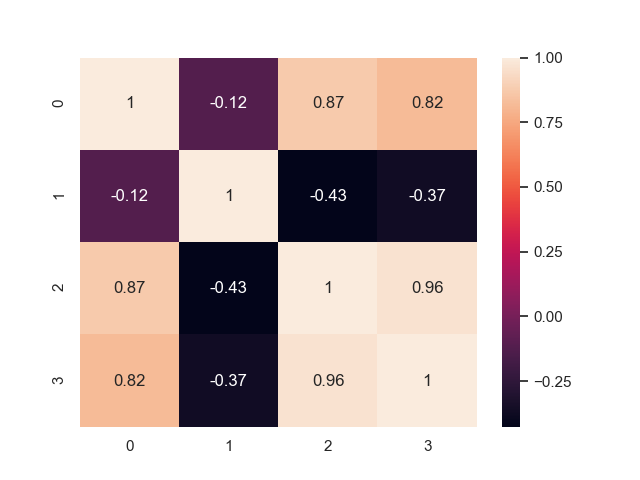
真ん中付近に「0.87」「0.82」「0.96」と説明変数同士でかなり高い相関値をもつものがあります。
この現象を「多重共線性」といいます。
多重共線性になると、変数間が独立ではないため解が計算できなかったり、信頼性が低下してしまいます。
そのため、高い相関値をもつ説明変数を取り除くなどの対策を取る必要があります。
【4】単純なロジスティック回帰分析の実装例
まずは、何の工夫もせずにそのままロジスティック回帰分析をしてみます。
今回はホールド・アウト方でデータセットを訓練用とテスト用に2分割して精度検証しています。

結果(予測精度)は学習データで92%、テストデータでは84%となり若干過学習に陥っています。
過学習とは、訓練データにモデルが稼業適合(オーバーフィッティング)しすぎているため、学習データとテストデータの結果に差が大きく出て、精度が落ちてしまう現象です。
過学習を防ぐには、「訓練データの数を増やす」「正則化などで学習時に一定の制約を与える」「質の良い説明変数のみを使う」などの対策を施します。
訓練データを増やすという対策は実際には難しいので、正則化や説明変数の選択という手法をまず取ることが多いです。
【5】L2正則化による過学習防止
ヒートマップを見た時に説明変数同士で相関係数が高いものがありました。
しかしながら、今回のケースは説明変数の数が少ないため、相関の高いものを取り除くというのは現実的ではありません。
そのような場合は、ロジスティック回帰に正則化項(L2ノルム)を加えることで、稼業適合(オーバーフィッティング)を抑えることができます。
学習データとテストデータのスコアの差が小さくなり、過学習が改善されています。



コメント