AIと機械学習の違いとは?基本用語から種類・活用事例まで幅広く解説します。
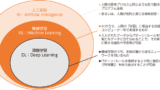
「AI」と「機械学習」の違いとは?
AI(人工知能)とは、「会話する」「画像を認識する」「意思決定する」といった「人間の知的活動を模倣する技術全般」を指します。
機械学習とは、AIを実現するための手法の1つで、「人間が経験から学ぶ仕組みをコンピュータで実現させる技術」のことです。また、深層学習は機械学習の中でも「特徴抽出も自動で行う高度な手法」のことです。
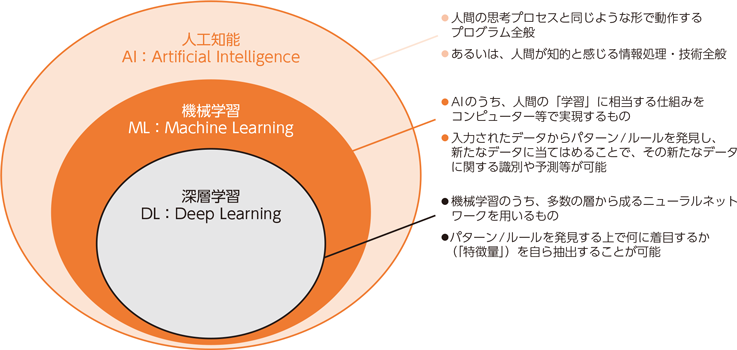
出典:総務省ホームページ (令和元年版 情報通信白書|AIに関する基本的な仕組み)
・AIは「上位概念」
・機械学習はその中の「学習技術」
・深層学習は機械学習の中でも「特徴抽出も自動で行う高度な手法」
コンピュータ技術の進歩とともに、機械学習の性能も大きく向上しており、今では私たちの生活のあらゆる分野で活用されています。
| 分野 | 活用例 |
|---|---|
| 金融 | ・株価や為替の予測 ・ローン審査における信用スコアリング ・不正取引の検出(フラウド検出) |
| 医療 | ・患者データから病気の判定(がん・糖尿病など) ・レントゲン画像の異常検知 ・新薬候補の探索(バイオインフォマティクス) |
| 自動車 | ・自動運転技術(物体認識、経路推定) ・ドライバーの疲労・注意力検知 ・エンジンや車両状態の異常予測 |
| 小売・EC | ・ユーザーの購買履歴からレコメンド ・在庫・需要の予測 ・顧客離脱予測 |
| 製造業 | ・工場設備の異常検知(予知保全) ・品質検査(画像認識) ・工程最適化(スループットの向上) |
今では、ビジネス業界や学術界の至る所で「AI」とう言葉が用いられています。しかし、私が学生の頃は(2010年代)、理工系の学術界で「AI」という語が過剰に期待を煽るマーケティング用語と見なされ、「研究テーマ名」や「論文タイトル」に使うのは避けられていました。代わりに「機械学習」「パターン認識」「深層学習(ディープラーニング)」など、より技術的かつ具体的な表現が用いられていました。
動画で見る
機械学習の基本
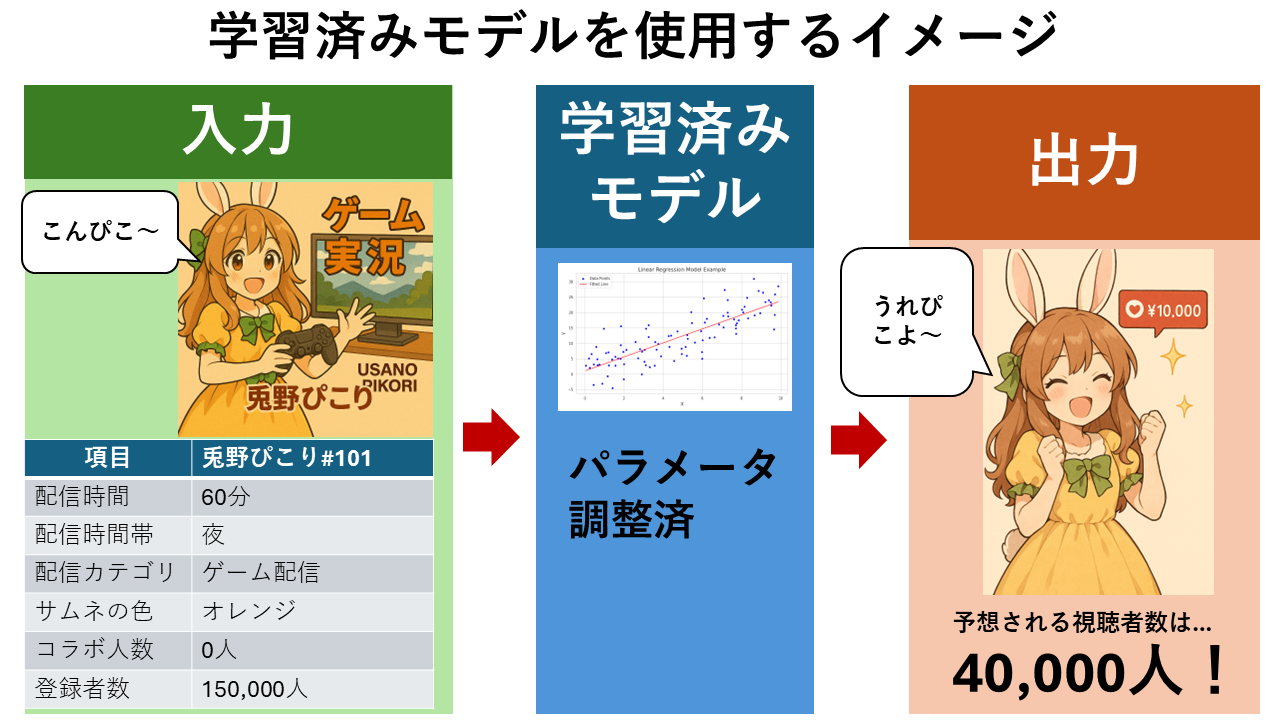
前節にて、機械学習は「人間が経験から学ぶ仕組みをコンピュータで実現させる技術」と説明しました。もう少し具体的に言うと、「事前に与えられたデータからパターンやルールを学習し、予測や判断を行う」技術です。人間が「経験」から学ぶように、コンピュータも多くのデータから「このパターンならこの結果になる」と学ぶことで賢くなっていきます。例えば、VTuberの配信における視聴者数を予想するとき、人間の経験と機械学習では以下のようになります。
【例】VTuberの配信における視聴者数の予想
| 項目 | 説明 |
|---|---|
| 人間の経験 | 「このVtuberは人気だから、夜のゲーム配信なら30,000人くらいは硬いだろう」などと予想 |
| 機械学習 | VTuber達の過去の配信履歴から視聴者数を予測するパターンやルールを学習。作成した学習済みモデルを利用して「VTuberの配信情報から視聴者数は40,000人」と予想 |
では、機械学習ではどのように「パターンやルールを学習」するのか解説します。以下は、機械学習により「視聴者数の予測」を行うモデルを構築するイメージです。
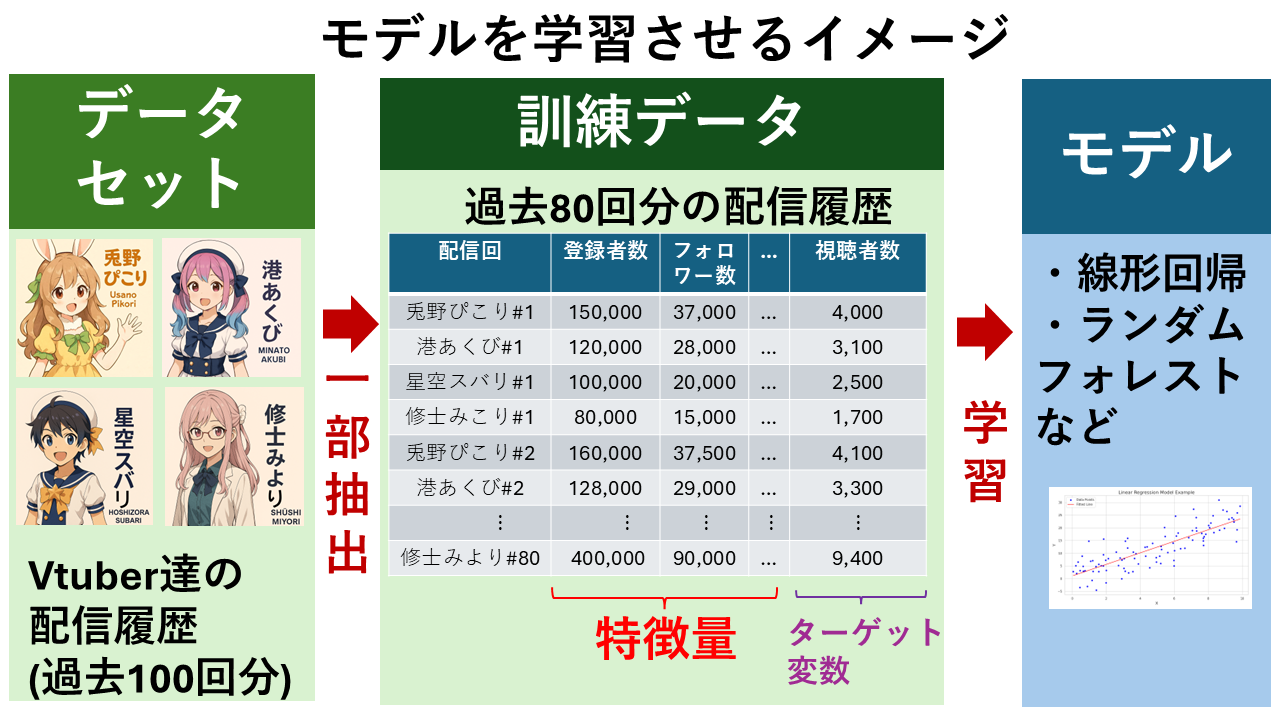
① データセットを作成します。
② データセットからモデルの学習に用いる特徴量(説明変数)を選定し、ターゲット変数(目的変数)とセットにして訓練データを作成します。
(ターゲット変数の例)視聴者数
③ 選定したモデルを、訓練データで学習します。
登場する単語の意味を以下にまとめました。最初は大体で理解しましょう。
| 用語 | 意味 | 例 |
|---|---|---|
| モデル | 入力データから出力を予測するための数理的な構造 | 「この配信は何人くらい見そうか?」を予測する関数やアルゴリズム(例:線形回帰、ランダムフォレスト)。 |
| 学習 | モデルが訓練データからパターンを見つけて、予測精度を高める | 過去の配信履歴を使って「どんな配信が人気か」をモデルが学ぶこと。 |
| データセット | モデルの学習や評価に使うデータの集合 | 複数のVTuberの配信履歴をまとめたデータ(CSVファイル、データベースなど)。 |
| 訓練データ | モデルの学習に使うデータセットの一部 | データセットから抽出した過去80回の配信履歴。 |
| ターゲット変数(目的変数) | モデルが予測・分類しようとする「答え」 | 配信の視聴者数(例:1200人) |
| 特徴量(説明変数) | モデルの学習時に入力として使う個々の情報 | 配信時間帯、配信カテゴリ、コラボ人数、登録者数などの視聴者数に影響する各項目。 |
| パラメータ | モデルが学習により決定する値。予測の計算式に使われる重みや係数。 | 線形回帰の傾きや切片など。 |
| ハイパーパラメータ | モデル設計時に手動で設定するパラメータ。 | 学習率、決定木の深さ、正則化係数など。 自動では学習されず、手動で調整することにより性能向上を図る。 |
以下は、機械学習により構築した「学習済みモデル」を用いて「視聴者数の予測」を行うイメージです。
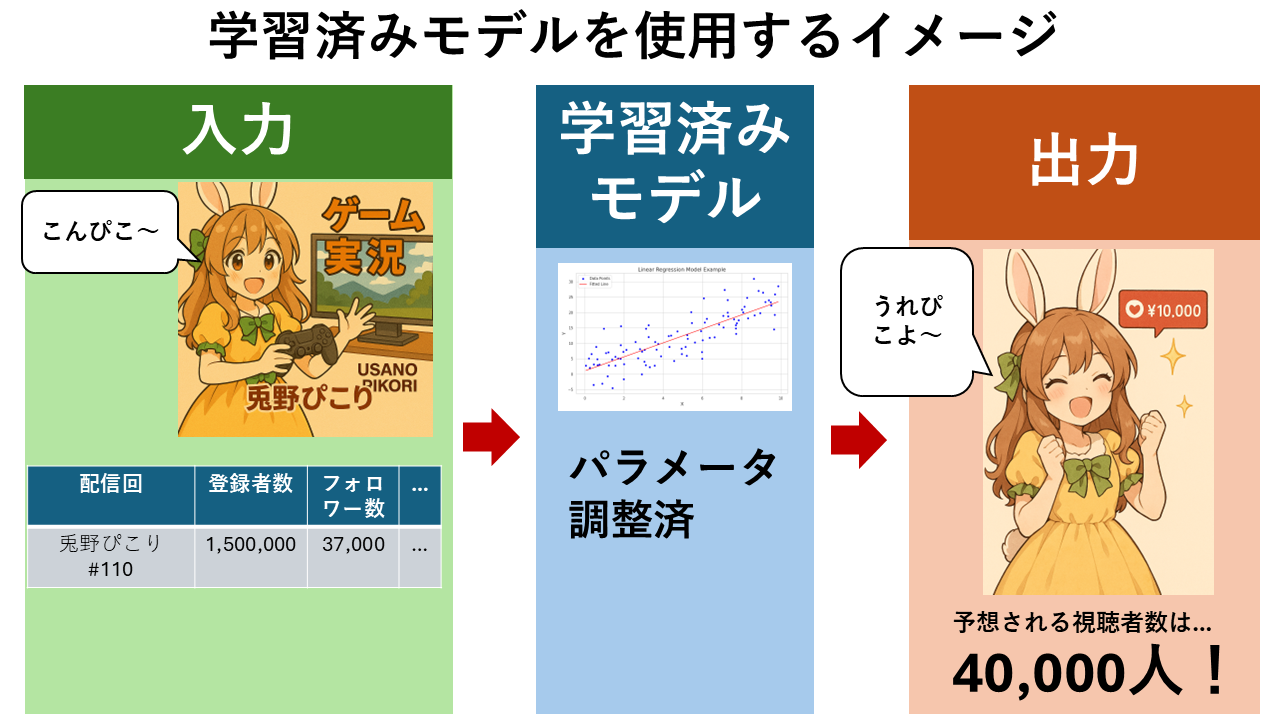
④ 学習済みモデルの性能を評価します。一般的には、テストデータをモデルに入力し、予測精度や汎化性能を確認します。
| 用語 | 意味 | 例 |
|---|---|---|
| 学習済みモデル | 学習が完了し、予測に使える状態のモデル(パラメータが調整済み) | 「この配信は視聴者数が1000人くらい」と予測できるようになったモデル。 |
| 入力 | モデルに与える情報(予測の材料) | 配信時間、カテゴリ、サムネ色、コラボ人数など。 |
| 出力 | モデルが予測する結果 | 視聴者数(例:1200人)。 |
| テストデータ | モデルの性能を評価するために使う、訓練に使用していないデータ | データセットから抽出した過去20回分の配信履歴(訓練データに未使用)。 |
| 過学習 | 学習データに過度に適合してしまい、汎化性能が低くなる問題 | 学習データには強いが、テストデータでは精度が落ちる |
| 汎化性能 | 未知のデータに対する予測精度 | 新しい配信でも視聴者数を正確に予測できるかどうか。精度が低ければ、過学習の抑制や交差検証によって改善 |
| 特徴量エンジニアリング | 学習性能を高めるために、データから新しい特徴量を作成するプロセス。 | 「配信日」から「曜日」を抽出、「カテゴリ」から「ジャンル傾向」を導くなど |
| 正則化 | モデルの複雑さを制御し、過学習を防ぐ技術 | L1正則化(特徴量の選別)、L2正則化(重みの抑制)など |
| 交差検証 | データを複数の分割にして、繰り返し学習・検証することでモデルの性能を安定して評価**する方法 | K-Fold交差検証で、配信履歴を5分割して検証 |
| 評価指標 | モデルの予測性能を測る基準 | 回帰ならMSE・R²、分類なら正解率・F1スコアなど |
| 未学習 | モデルが訓練データにすら適合できていない状態 | モデルが単純すぎて、視聴者数の傾向を捉えられない |
⑤ 実際のデータに適用し、運用開始します。
学習手法やモデルを選ぶ際のポイント
学習手法やモデルを選ぶ際には、次の要素をバランスよく考慮する必要があります。なお、一般的に「解釈のしやすさ」と「予測性能」はトレードオフになることが多いです。
・予測精度
・学習時間と実装・運用コスト
・利用可能なデータの量・質
・結果の解釈のしやすさ(説明可能性)
バランスの良い選択を行うには、各手法の数理的な理解が必要です。機械学習の仕組みについては、以下ページで詳しく学ぶことができます。
Pythonライブラリ「Scikit-learn」を用いた機械学習の実装方法については、以下ページで詳しく学ぶことができます。



コメント