
Haar-Like特徴量の基本的な原理や仕組みについてまとめました。
【はじめに】Haar-Like特徴量とは
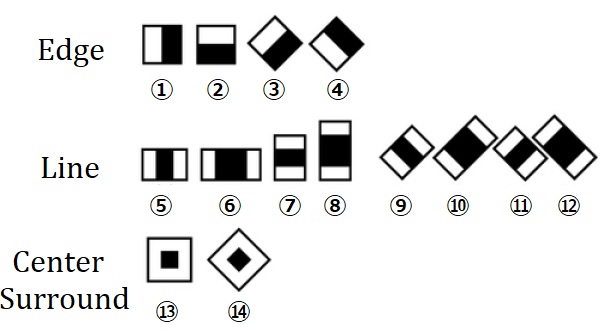
Haar-Like特徴では、次のような矩形領域のパターンを設定し、白領域に対応する画素の和と、黒領域に対応する画素の和の差を特徴量とします。


画素値をそのまま用いる場合と比べて、照明条件の変動やノイズの影響を受けにくくなる利点があり、顔検出などに使われています。
例えば、顔の目の部分は、「目玉が暗い」「目元は明るい」というのが大体誰でも共通しています。
このような特徴をたくさん取ることで顔全体の特徴を捉えていきます。
【アルゴリズム】Haar-Like特徴量の計算
①Haar-like特徴に用いるパターンを複数用意します。
②入力画像の任意の位置に探索窓を配置します。
③探索窓の任意の位置に矩形領域を配置します。

④矩形領域に任意のパターンを設定します。

⑤パターンの黒領域、白領域それぞれの画素値の和の平均 を求めます。
を求めます。
そして、それらの差を特徴量 とします。
とします。
(1) 
画素値の和の計算には積分画像を用いること処理を高速化します。

【積分画像とは】計算方法と高速化の仕組み
積分画像とは?計算方法と高速化の仕組みについてまとめました。
algorithm.joho.info
2017.07.19
⑥矩形領域の位置・サイズ・パターンを変えて⑤の計算を繰り返します。
⑦検索窓の位置を変えて②~⑥を繰り返します。
【高速化】ブースティング(Boosting)
探索窓のサイズにもよりますが、矩形領域の位置・サイズ・パターンの組み合わせの総数は膨大です。
したがって、計算した特徴量全てをそのまま使って顔検出などに利用すると、計算時間が膨大になってしまいます。
そこで、学習によって決定した重要度が高い特徴量のみを使うことで、計算時間を短縮します。
これをブースティング(Boosting)といいます。
【例】
入力画像のサイズが24×24[px]の場合・・・特徴量候補は約18万個
ブースティング・・・重要度が高い数百~数千個の特徴量のみを選択
入力画像のサイズが24×24[px]の場合・・・特徴量候補は約18万個
ブースティング・・・重要度が高い数百~数千個の特徴量のみを選択
【機械学習】ブースト(boost・AdaBoost)の原理・計算式
機械学習で識別器の作成などに使われるブースト(boost・AdaBoost)のアルゴリズムや計算についてまとめました。
algorithm.joho.info
2020.01.23
画像処理
「画像処理」の記事一覧です。
algorithm.joho.info

コメント