この記事では、機械学習におけるカスケード型識別器(分類器)のアルゴリズムや計算についてまとめました。
カスケード型識別器とは
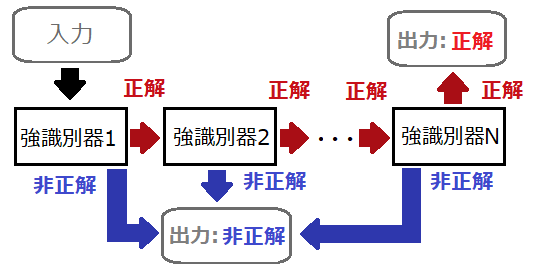
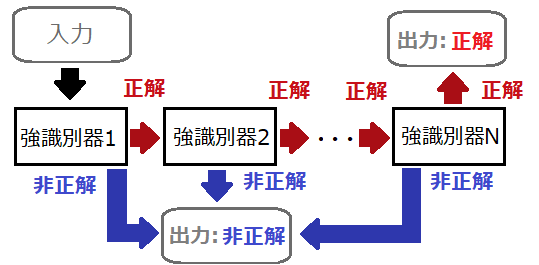
カスケード型識別器(Cascade detector)は、複数の強識別器を連結した識別器です。
カスケード型識別器では、各強識別器により順番に判別を行います。
最初の強識別器1で「正解」と判別されると、その次の強識別器2でまた判別を行います。
これを繰り返し、強識別器Nまで一貫して「正解」になった場合のみ、結果を正解として出力します。
途中で「非正解」と判別すれば結果は非正解として出力し、処理を終了します。
具体例(顔検出の場合)
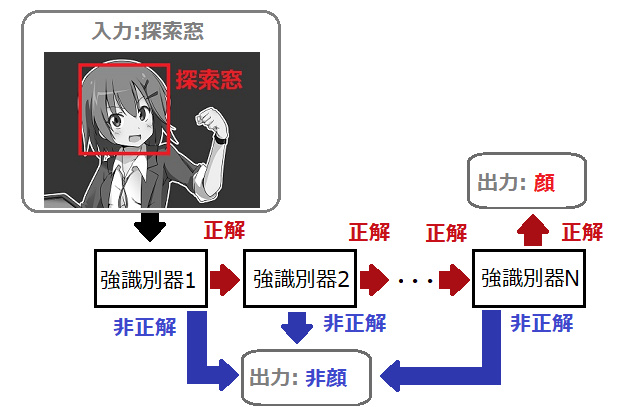
カスケード型識別器の理解を深めるために、顔検出のケースで説明します。
その場合、「入力」「正解」「非正解」の内容は次のようになります。
| – | 内容 |
|---|---|
| 入力 | 探索窓画像 |
| 正解 | 顔画像である |
| 非正解 | 顔画像でない |
強識別器1~Nまで一貫して「顔画像である」と判別された場合のみ「探索窓画像中には顔画像がある」とします。
途中で強識別器が「顔画像でない」と判別すれば処理を終了し、「探索窓画像中には顔画像がない」とします。
カスケード型識別器の利点
カスケード型識別器の利点は処理を高速化できる点です。
カスケード型識別器では、手前にある強識別器ほど判別基準を緩く(誤検出を高く)します。
判別基準を緩くすると、判別に使用する特徴数が少なくなるため、計算時間は短くなります。
よって、非正解の入力を手前の強識別器で素早く排除でき、全体の処理を高速化できます。
顔検出の場合、入力画像の探索窓は非顔領域である確率が高いです。
よって、非顔領域をいかに素早く排除するかが高速化の肝になります。
カスケード型識別器の作り方
カスケード型識別器の作り方は次の通りです。
| – | 説明 |
|---|---|
| 1 | N個の識別器それぞれに対して目標値(最小検出率 と最大許容誤検出率 と最大許容誤検出率 )を設定します。 )を設定します。 |
| 2 | 教師データ(正解・非正解データ)を用意します。 |
| 3 | N個の強識別器をAdaBoostで順に学習させます。 |
| 3.1 |  番目の強識別器に弱識別器を1つ追加します。(最初は 番目の強識別器に弱識別器を1つ追加します。(最初は ) ) |
| 3.2 | 強識別器に教師データを与えて、判別を行わせます。 |
| 3.3 | 判別結果が目標値を満たすよう、強識別器の閾値を下げます。(※誤検出率は高くなる) |
| 3.4 | 誤検出率が目標値を満たせばAdaBoost学習を終了し、手順3.5に進みます。満たさなければ手順3.1に戻って学習を続けます。 |
| 3.5 | 判別を誤った非正解データのみを、次の強識別器を求めるのに使用する非正解データとします。 |
| 3.6 | 手順3.1に戻り、次の強識別器を作成します。( ) ) |
前節で述べた通り、高速化のために手前にある強識別器に対しては最大許容誤検出率を高めに設定します。
AdaBoostによる学習の原理については下記事で解説しています。
【参考】AdaBoostの原理・計算式
参考文献
[1] Paul Viola, Michael Jones “Rapid Object Detection using a Boosted Cascade of Simple Features” (2001)
【関連記事】
【画像処理入門】アルゴリズム&プログラミング

コメント
強識別器ではなく弱識別器ではないでしょうか