
この記事では、Python2で日本語を使う方法をソースコード付きで解説します。
日本語の扱い方
Python2.xでは、UTF-8、Shift-JIS、 EUC-JPなどの文字コードとは別にUnicode文字列というものが存在します。
PythonではUnicode文字列を使って日本語を扱うことが出来ます。
Unicode文字列の使った日本語の扱い方はいくつかあります。
# -*- coding: utf-8 -*-
data1 = u"にゃんぱす"
data2 = unicode("にゃんぱす", "utf-8")
1行目は、ソースコード中に日本語文字を書く場合に使います。
2行目は、ファイルなどから読み込んだ文字列を変換する場合に使います。
また、UnicodeからUTF-8, Shift-JIS, EUC-JPへ変換するには以下のようにします。
# -*- coding: utf-8 -*-
data = u"にゃんぱす"
data.encode("utf-8")
data.encode("shift-jis")
data.encode("euc-jp")
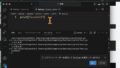
逆にUTF-8, Shift-JIS, EUC-JPからUnicodeへ変換するには以下のようにします。
# -*- coding: utf-8 -*- data = "にゃんぱす" unicode(data, "utf-8")

コメント