漏れ電流測定試験の結果データ(CSVファイル)をPythonで解析する方法についてまとめました。
【ファイル操作】CSVファイルの読み込み①
HIOKIデータロガーのデータは、時系列データなのでPandasモジュールを使うと扱いやすいです。
ただし、HIOKIデータロガーで出力されたCSVファイルはShift-JIS形式で保存されているため、読み込むときは「Shift-JIS」を指定します。
"Header Size" ,15 "Model Name" ,"DL850EV " "Comment" ," " "BlockNumber" ,1 "TraceName" ,"CH1 " "BlockSize" ,6006 "VUnit" ,"A " "SampleRate" ,10.000000 "HResolution" ,1.000000e-01 "HOffset" ,0.000000e+00 "HUnit" ,"s " "DisplayPointNo." ,1 "PhaseShift" ,1 "Date" ,"2022/05/07 " "Time" ,"14:22:41.55125431" ,-5.0000E-10, ,-5.0000E-10, ,-5.0000E-10, ,-5.0000E-10, (略)
# -*- coding: utf-8 -*-
# -*- coding: utf-8 -*-
import pandas as pd
# CSVファイルのロード
df = pd.read_csv("/Users/github/sample/python/pandas/sample/sample01_analyze_leak-current/data.csv", skiprows = 16)
# データフレームを表示
print(df)
"""
Unnamed: 0 -5.0000E-10 Unnamed: 2
0 NaN -5.000000e-10 NaN
1 NaN -5.000000e-10 NaN
2 NaN -5.000000e-10 NaN
3 NaN -5.833300e-10 NaN
4 NaN -5.000000e-10 NaN
... ... ... ...
6000 NaN 7.820800e-07 NaN
6001 NaN 7.781700e-07 NaN
6002 NaN 7.826700e-07 NaN
6003 NaN 7.741700e-07 NaN
6004 NaN 7.731700e-07 NaN
[6005 rows x 3 columns]
"""
【ファイル操作】CSVファイルの読み込み②
HIOKIデータロガーのCSVデータは、最初の数行に邪魔な情報が入っており、そのまま読み込むとヘッダ行を誤ってしまいます。
そこで、最初の数行を読み飛ばします。
# -*- coding: utf-8 -*-
import pandas as pd
csv_path = "C:\prog\python\hioki\sample.csv"
# CSVファイルのロード
df_raw = pd.read_csv(csv_path, encoding="SHIFT-JIS")
# 列数、行数の取得
rows, columns = df_raw.shape
# ある行数(列数+4)を読み飛ばしてデータフレームに格納
df = pd.read_csv(csv_path, encoding="SHIFT-JIS", skiprows = columns+4)
# データフレームを表示
print(df)
"""
Time CH1-1-1[℃] CH1-1-2[℃] CH1-1-3[℃] CH1-1-4[V] CH1-1-5[V] CH1-1-6[V] CH1-1-7[V]
0 18-09-24 09:55:00s 26.2 26.3 24.8 20.7 20.7 20.7 20.7
1 18-09-24 09:55:01s 26.2 26.3 24.8 20.7 20.7 20.7 20.7
2 18-09-24 09:55:02s 26.2 26.3 24.8 20.7 20.7 20.7 20.7
3 18-09-24 09:55:03s 26.2 26.3 24.8 20.7 20.7 20.7 20.7
4 18-09-24 09:55:04s 26.2 26.3 24.8 20.7 20.7 20.7 20.7
... ... ... ... ... ... ... ... ...
11107 18-09-24 13:00:07s 26.8 24.8 26.1 20.8 20.8 20.3 20.3
11108 18-09-24 13:00:08s 26.8 24.8 26.1 20.8 20.8 20.3 20.3
11109 18-09-24 13:00:09s 26.8 24.8 26.1 20.8 20.8 20.3 20.3
[11110 rows x 8 columns]
"""
【データ抽出①】特定のチャンネルを選択・抽出
ヘッダ行を正しく読み込めれば、Pandasの本領発揮です。
以下のように簡単に特定のチャンネルを選択・抽出できます。
# -*- coding: utf-8 -*-
import pandas as pd
csv_path = "C:\prog\python\hioki\sample.csv"
# CSVファイルのロード
df_raw = pd.read_csv(csv_path, encoding="SHIFT-JIS")
# 列数、行数の取得
rows, columns = df_raw.shape
# ある行数(列数+4)を読み飛ばしてデータフレームに格納
df = pd.read_csv(csv_path, encoding="SHIFT-JIS", skiprows = columns+4)
# 時刻の列を取り出し
print(df['Time'])
"""
0 18-09-24 09:55:00s
1 18-09-24 09:55:01s
2 18-09-24 09:55:02s
...
11107 18-09-24 13:00:07s
11108 18-09-24 13:00:08s
11109 18-09-24 13:00:09s
Name: Time, Length: 11110, dtype: object
"""
# チャンネル1のデータを取り出し
print(df['CH1-1-1[℃]'])
"""
0 26.2
1 26.2
2 26.2
...
11107 26.8
11108 26.8
11109 26.8
Name: CH1-1-1[℃], Length: 11110, dtype: float64
"""
# 時刻、チャンネル1、3、5のデータを取り出し
df.loc[:, ['Time','CH1-1-1[℃]', 'CH1-1-3[℃]', 'CH1-1-5[V]']]
"""
Time CH1-1-1[℃] CH1-1-2[℃] CH1-1-3[℃]
0 18-09-24 09:55:00s 26.2 26.3 24.8
1 18-09-24 09:55:01s 26.2 26.3 24.8
2 18-09-24 09:55:02s 26.2 26.3 24.8
...
11107 18-09-24 13:00:07s 26.8 24.8 26.1
11108 18-09-24 13:00:08s 26.8 24.8 26.1
11109 18-09-24 13:00:09s 26.8 24.8 26.1
[11110 rows x 4 columns]
"""
【データ抽出②】特定の時間帯・チャンネルのデータを取り出し
# -*- coding: utf-8 -*-
import pandas as pd
# CSVファイルのパス
csv_path = "C:\prog\python\hioki\sample.csv"
# CSVファイルのロード
df_raw = pd.read_csv(csv_path, encoding="SHIFT-JIS")
# 列数、行数の取得
rows, columns = df_raw.shape
# ある行数(列数+4)を読み飛ばしてデータフレームに格納
df = pd.read_csv(csv_path, encoding="SHIFT-JIS", skiprows = columns+4)
# インデックスに「Time」列を設定
df.set_index('Time', inplace=True)
# 特定の時間帯、チャンネルのデータを抽出
df2 = df.loc['18-09-24 09:55:00s':'18-09-24 09:55:05s', ['CH1-1-1[℃]', 'CH1-1-3[℃]', 'CH1-1-5[V]']]
print(df2)
""" CH1-1-1[℃] CH1-1-3[℃] CH1-1-5[V]
Time
18-09-24 09:55:00s 26.2 24.8 20.7
18-09-24 09:55:01s 26.2 24.8 20.7
18-09-24 09:55:02s 26.2 24.8 20.7
18-09-24 09:55:03s 26.2 24.8 20.7
18-09-24 09:55:04s 26.2 24.8 20.7
18-09-24 09:55:05s 26.2 24.8 20.7
"""
【統計量】各列の平均値、合計値、最大値、最小値などを計算
# -*- coding: utf-8 -*-
import pandas as pd
# CSVファイルのパス
csv_path = "C:\prog\python\hioki\sample.csv"
# CSVファイルのロード
df_raw = pd.read_csv(csv_path, encoding="SHIFT-JIS")
# 列数、行数の取得
rows, columns = df_raw.shape
# ある行数(列数+4)を読み飛ばしてデータフレームに格納
df = pd.read_csv(csv_path, encoding="SHIFT-JIS", skiprows = columns+4)
# インデックスに「Time」列を設定
df.set_index('Time', inplace=True)
# 特定の時間帯、チャンネルのデータを抽出
df2 = df.loc['18-09-24 09:55:00s':'18-09-24 09:55:05s', ['CH1-1-1[℃]', 'CH1-1-3[℃]', 'CH1-1-5[V]']]
# 合計
sum = df2['CH1-1-1[℃]'].sum()
# 平均
mean = df['CH1-1-1[℃]'].mean()
# 中央値
median = df['CH1-1-1[℃]'].median()
# 最大値
dfmax = df['CH1-1-1[℃]'].max()
# 最小値
dfmin = df['CH1-1-1[℃]'].min()
# データ数
N = df['CH1-1-1[℃]'].count()
# 標準偏差
std = df['CH1-1-1[℃]'].std()
# 分散
var = df['CH1-1-1[℃]'].var()
# 計算結果の表示
print("sum:", sum)
print("mean:", mean)
print("median:", median)
print("max:", dfmax)
print("min:", dfmin)
print("N:", N)
print("std:", std)
print("var:", var)
"""
sum: 157.2
mean: 25.995472547254657
median: 26.1
max: 26.9
min: 24.1
N: 11110
std: 0.7353111816795675
var: 0.5406825339030019
"""
統計量の出力
describe()メソッドだともっと簡単に基本統計量を計算できます。
また、to_csv()メソッドと組み合わせることで計算結果をCSVに出力できます。
# -*- coding: utf-8 -*-
import pandas as pd
# CSVファイルのパス
csv_path = "C:\prog\python\hioki\sample.csv"
# CSVファイルのロード
df_raw = pd.read_csv(csv_path, encoding="SHIFT-JIS")
# 列数、行数の取得
rows, columns = df_raw.shape
# ある行数(列数+4)を読み飛ばしてデータフレームに格納
df = pd.read_csv(csv_path, encoding="SHIFT-JIS", skiprows = columns+4)
# インデックスに「Time」列を設定
df.set_index('Time', inplace=True)
# 特定の時間帯、チャンネルのデータを抽出
df2 = df.loc['18-09-24 09:55:00s':'18-09-24 09:55:05s', ['CH1-1-1[℃]', 'CH1-1-3[℃]', 'CH1-1-5[V]']]
# 統計量を計算し、csvファイルに出力
df2.describe().to_csv(csv_path + "_describe.csv")
"""
出力されたCSVの中身
,CH1-1-1[℃],CH1-1-3[℃],CH1-1-5[V]
count,6.0,6.0,6.0
mean,26.2,24.8,20.7
std,0.0,0.0,0.0
min,26.2,24.8,20.7
25%,26.2,24.8,20.7
50%,26.2,24.8,20.7
75%,26.2,24.8,20.7
max,26.2,24.8,20.7
"""
| – | 関連記事 |
|---|---|
| 1 | 【Pandas】列の合計、平均、中央、分散、標準偏差、最大、最小、他を計算 |
【グラフ化】Matplotlibで普通に表示
PandasのplotメソッドとMatplotlibで普通にグラフ化してみます。
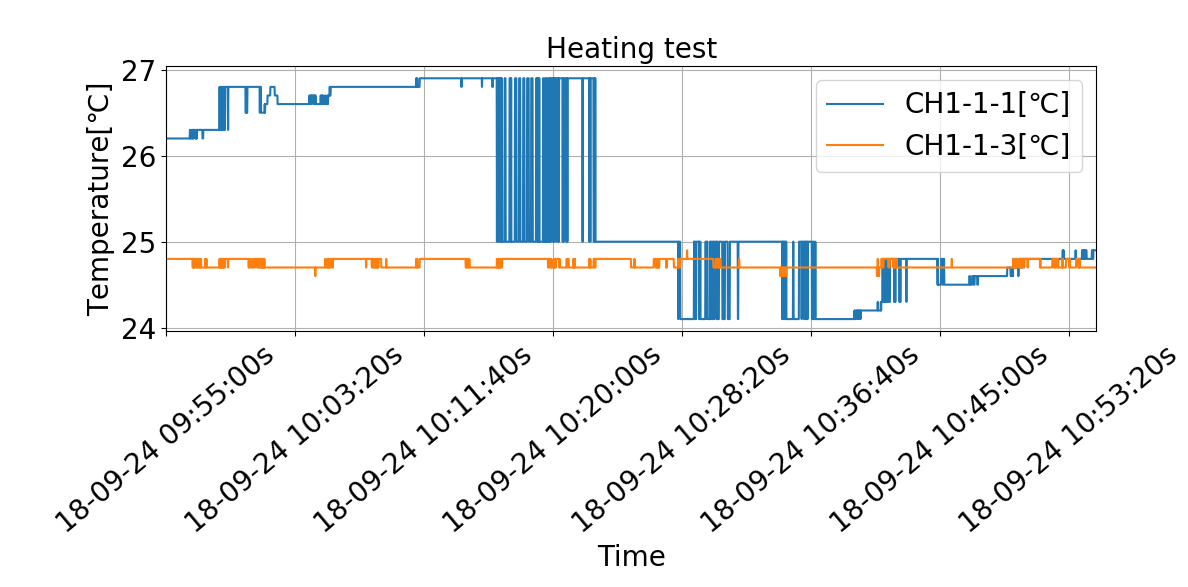
# -*- coding: utf-8 -*-
import pandas as pd
import matplotlib
import matplotlib.pyplot as plt
# CSVファイルのパス
csv_path = "C:\prog\python\hioki\sample.csv"
# CSVファイルのロード
df_raw = pd.read_csv(csv_path, encoding="SHIFT-JIS")
# 列数、行数の取得
rows, columns = df_raw.shape
# ある行数(列数+4)を読み飛ばしてデータフレームに格納
df = pd.read_csv(csv_path, encoding="SHIFT-JIS", skiprows = columns+4)
# インデックスに「Time」列を設定
df.set_index('Time', inplace=True)
# 特定の時間帯、チャンネルのデータを抽出
df2 = df.loc['18-09-24 09:55:00s':'18-09-24 10:55:05s', ['CH1-1-1[℃]', 'CH1-1-3[℃]']]
# グラフ化
df2.plot()
plt.legend(loc=1,fontsize=20) # 凡例の表示(1:位置は第1象限)
plt.title('Heating test', fontsize=20) # グラフタイトル
plt.xlabel('Time', fontsize=20) # x軸ラベル
plt.xticks(rotation=40)
plt.ylabel('Temperature[℃]', fontsize=20) # y軸ラベル
#plt.xlim([-3, 3]) # x軸範囲
#plt.ylim([-2, 4]) # y軸範囲
plt.tick_params(labelsize = 20) # 軸ラベルの目盛りサイズ
#plt.xticks(np.arange(-3.0, 4.0, 1.0)) # x軸の目盛りを引く場所を指定(無ければ自動で決まる)
#plt.yticks(np.arange(-3.0, 4.0, 1.0)) # y軸の目盛りを引く場所を指定(無ければ自動で決まる)
plt.tight_layout() # ラベルがきれいに収まるよう表示
plt.grid() # グリッドの表示
plt.show() # グラフ表示
| – | 関連記事 |
|---|---|
| 1 | 【Matplotlib入門】サンプル集 |
【グラフ化】時刻を経過時間にする
x軸ラベル(時刻)が長すぎて汚くなるため、x軸ラベルを「経過時間」に変更します。
HIOKI標準の時刻表記「’18-09-24 09:55:00s」は扱いにくいため、時刻先頭の「’」を「20」に置換し、さらにISO8601形式の時刻表記に変換しています。
そうすることで、経過時間の計算等が簡単になります。
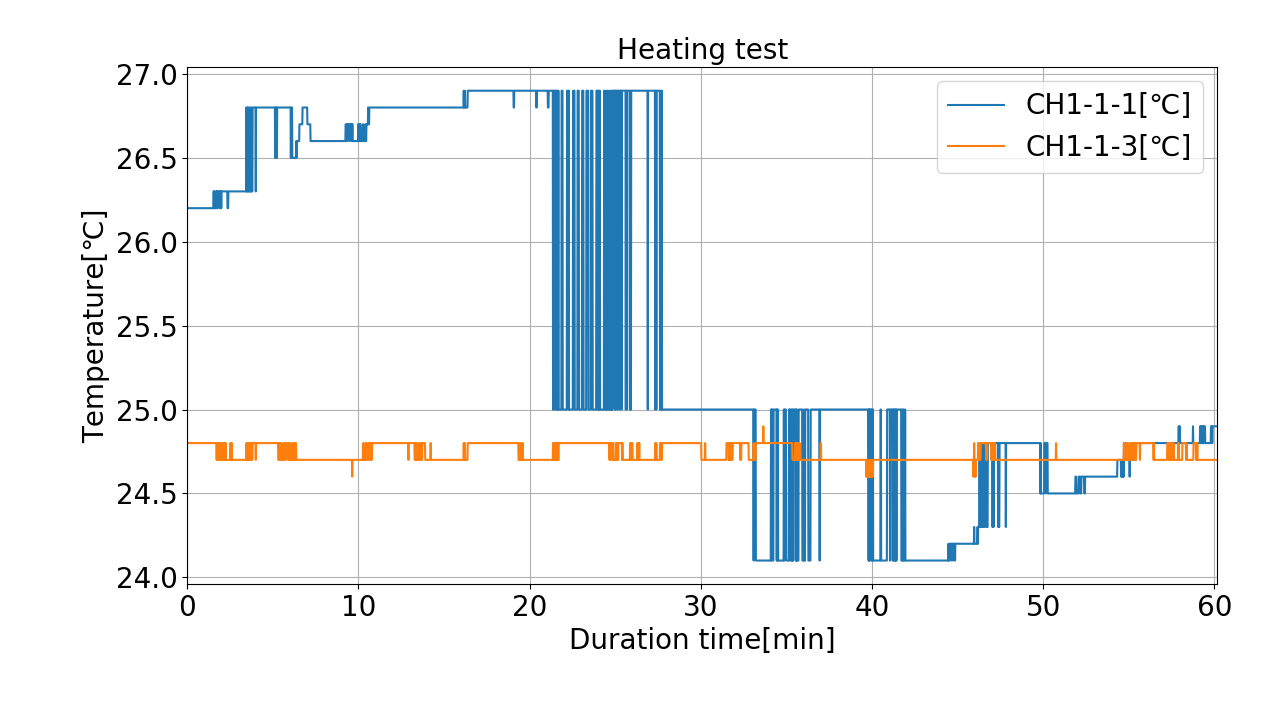
# -*- coding: utf-8 -*-
import pandas as pd
import matplotlib
import matplotlib.pyplot as plt
from datetime import datetime as dt
import numpy as np
# CSVファイルのパス
csv_path = "C:\prog\python\hioki\sample.csv"
start_time = '2018-09-24 09:55:00'
end_time = '2018-09-24 10:55:10'
ch_label = ['CH1-1-1[℃]', 'CH1-1-3[℃]']
# CSVファイルのロード
df_raw = pd.read_csv(csv_path, encoding="SHIFT-JIS")
# 列数、行数の取得
rows, columns = df_raw.shape
# ある行数(列数+4)を読み飛ばしてデータフレームに格納
df = pd.read_csv(csv_path, encoding="SHIFT-JIS", skiprows = columns+4)
# 時刻先頭の「'」を「20」に置換
df['Time'] = df['Time'].str.replace("\'", "20")
# ISO8601形式の時刻表記に変換
df['Time'] = pd.to_datetime(df['Time'], format='%Y-%m-%d %H:%M:%Ss')
# インデックスに「Time」列を設定
df.set_index('Time', inplace=True)
# 特定の時間帯、チャンネルのデータを抽出
df2 = df.loc[start_time:end_time, ch_label]
# 経過時間[HH:MM:SS]の計算
df2['Duration time[HH:MM:SS]'] = df2.index.to_series() - pd.to_datetime(start_time)
# 経過時間[sec]の計算
df2['Duration time[sec]'] = df2['Duration time[HH:MM:SS]'].apply(lambda x: x / np.timedelta64(1, 's'))
# 経過時間[min]の計算
df2['Duration time[min]'] = df2['Duration time[HH:MM:SS]'].apply(lambda x: x / np.timedelta64(1, 'm'))
# グラフ化
df2.plot(x='Duration time[min]', y=ch_label)
plt.legend(loc=1,fontsize=20) # 凡例の表示(1:位置は第1象限)
plt.title('Heating test', fontsize=20) # グラフタイトル
plt.xlabel('Duration time[min]', fontsize=20) # x軸ラベル
plt.ylabel('Temperature[℃]', fontsize=20) # y軸ラベル
plt.tick_params(labelsize = 20) # 軸ラベルの目盛りサイズ
plt.tight_layout() # ラベルがきれいに収まるよう表示
plt.grid() # グリッドの表示
plt.show() # グラフ表示
【グラフ化】綺麗に整える
カラム名を好きな名前に変えます。
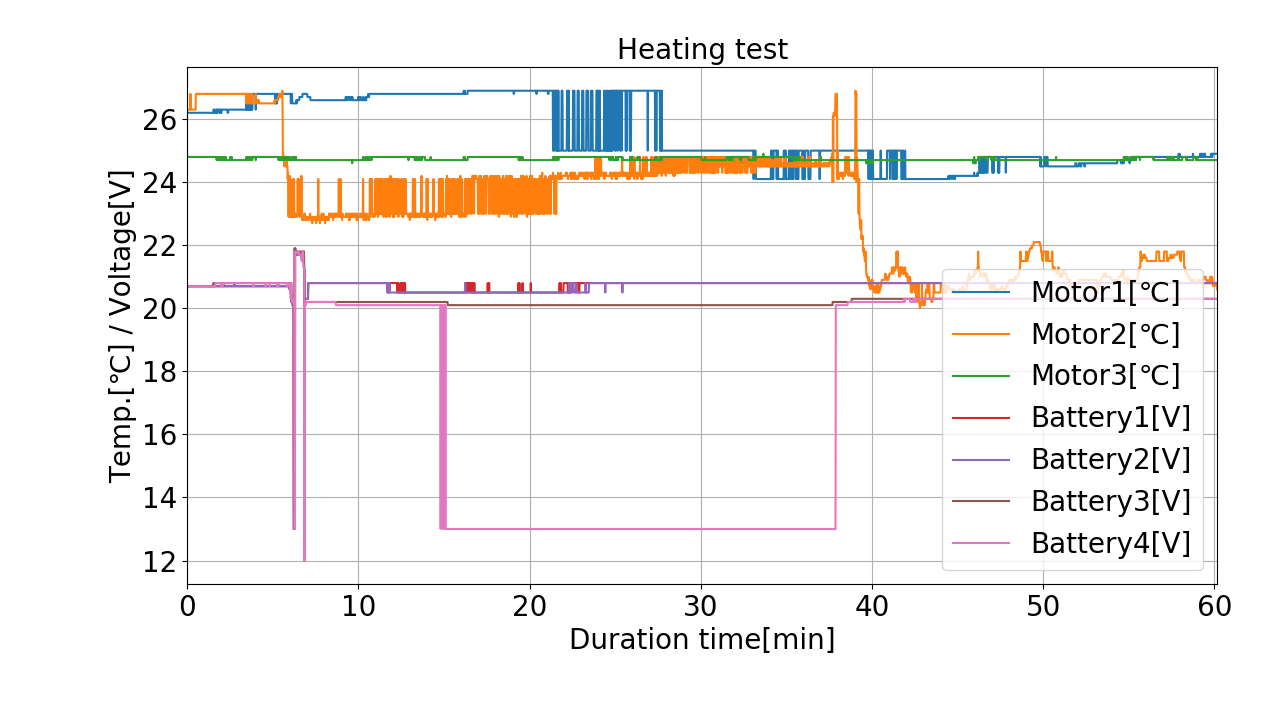
# -*- coding: utf-8 -*-
import pandas as pd
import matplotlib
import matplotlib.pyplot as plt
from datetime import datetime as dt
import numpy as np
# CSVファイルのパス
csv_path = "C:\prog\python\hioki\sample.csv"
# 抽出する時刻(最初の時刻、最後の時刻)
start_time = '2018-09-24 09:55:00'
end_time = '2018-09-24 10:55:10'
# 新しいカラム名
rename_label = ['Motor1[℃]', 'Motor2[℃]', 'Motor3[℃]', 'Battery1[V]', 'Battery2[V]', 'Battery3[V]', 'Battery4[V]']
# CSVファイルのロード
df_raw = pd.read_csv(csv_path, encoding="SHIFT-JIS")
# 列数、行数の取得
rows, columns = df_raw.shape
# ある行数(列数+4)を読み飛ばしてデータフレームに格納
df = pd.read_csv(csv_path, encoding="SHIFT-JIS", skiprows = columns+4)
# 時刻先頭の「'」を「20」に置換
df['Time'] = df['Time'].str.replace("\'", "20")
# ISO8601形式の時刻表記に変換
df['Time'] = pd.to_datetime(df['Time'], format='%Y-%m-%d %H:%M:%Ss')
# インデックスに「Time」列を設定
df.set_index('Time', inplace=True)
# カラム名の変更
df.columns = rename_label
# 特定の時間帯、チャンネルのデータを抽出
df2 = df.loc[start_time:end_time, rename_label]
# 経過時間[HH:MM:SS]の計算
df2['Duration time[HH:MM:SS]'] = df2.index.to_series() - pd.to_datetime(start_time)
# 経過時間[sec]の計算
df2['Duration time[sec]'] = df2['Duration time[HH:MM:SS]'].apply(lambda x: x / np.timedelta64(1, 's'))
# 経過時間[min]の計算
df2['Duration time[min]'] = df2['Duration time[HH:MM:SS]'].apply(lambda x: x / np.timedelta64(1, 'm'))
# グラフ化
df2.plot(x='Duration time[min]', y=df.columns)
plt.legend(loc=4,fontsize=20) # 凡例の表示(4:位置は第4象限)
plt.title('Heating test', fontsize=20) # グラフタイトル
plt.xlabel('Duration time[min]', fontsize=20) # x軸ラベル
plt.ylabel('Temp.[℃] / Voltage[V]', fontsize=20) # y軸ラベル
plt.tick_params(labelsize = 20) # 軸ラベルの目盛りサイズ
plt.tight_layout() # ラベルがきれいに収まるよう表示
plt.grid() # グリッドの表示
plt.show() # グラフ表示
| – | 関連記事 |
|---|---|
| 1 | ■Python入門 サンプル集 |
| 2 | ■【Pandas入門】データ分析のサンプル集 |


コメント