Pythonと深層学習ライブラリ「Keras」の学習過程(損失関数、評価関数の推移)をグラフ化する方法についてまとめました。
【Keras】損失関数、評価関数の推移をグラフ化
「Keras」の学習過程(損失関数、評価関数の推移)をグラフ化してみます。
動画解説
本ページの内容は以下動画でも解説しています。
補足
train、validation、test datasetの違いは以下のとおりです。
| 項目 | 概要 |
|---|---|
| train dataset | 分類器のパラメータを更新するための学習用データ。(ニューラルネットワークだと重みを更新) |
| validation dataset | ハイパーパラメータ(人が調整するパラメータ)の良し悪しを確かめるための検証用データ。学習は行わない。(ニューラルネットワークだと各層のニューロン数、隠れ層の数、バッチサイズ、学習係数など。ニューラルネットワークの重みは自動更新されるのでハイパーパラメータには含まれない) |
| test dataset | 学習後に汎化性能を確かめるために、最後に(理想的には一度だけ)テストするためのデータなので検証用データ(validation dataset)とは分ける。学習は行わない。 |
検証用データセット(validation)は、人の手によって設定されるパラメータ(ハイパーパラメータ)を調整するための、分類器のパフォーマンス測定に使います。
一方、テスト用データセット(test)は、学習後の分類器のパフォーマンスを確かめるためだけに使用します(テスト後には、それ以上分類器のハイパーパラメータを調整してはいけません。
もし、検証用データセット(validation)を使ってテストを行えば(学習後の分類器のパフォーマンスを確かめると)、学習には未使用のテスト用データセット(test)を使うよりも良い結果が得られてしまいます。
つまり、実際よりもエラー率が低くなってしまい、最終的なパフォーマンス計測には不適なので、未使用のデータセットとしてのテストセットを用意しておく必要があります。
サンプルコード
model.fitのパラメーターに「validation_split」や「validation_data」という検証用データの設定を与えておくと、model.fitの返り値のhistoryオブジェクトにepoch毎の訓練データでの評価に加えて検証用データ(validation)での評価も結果を記録してくれます。
その結果をグラフ出力したものが以下になります。
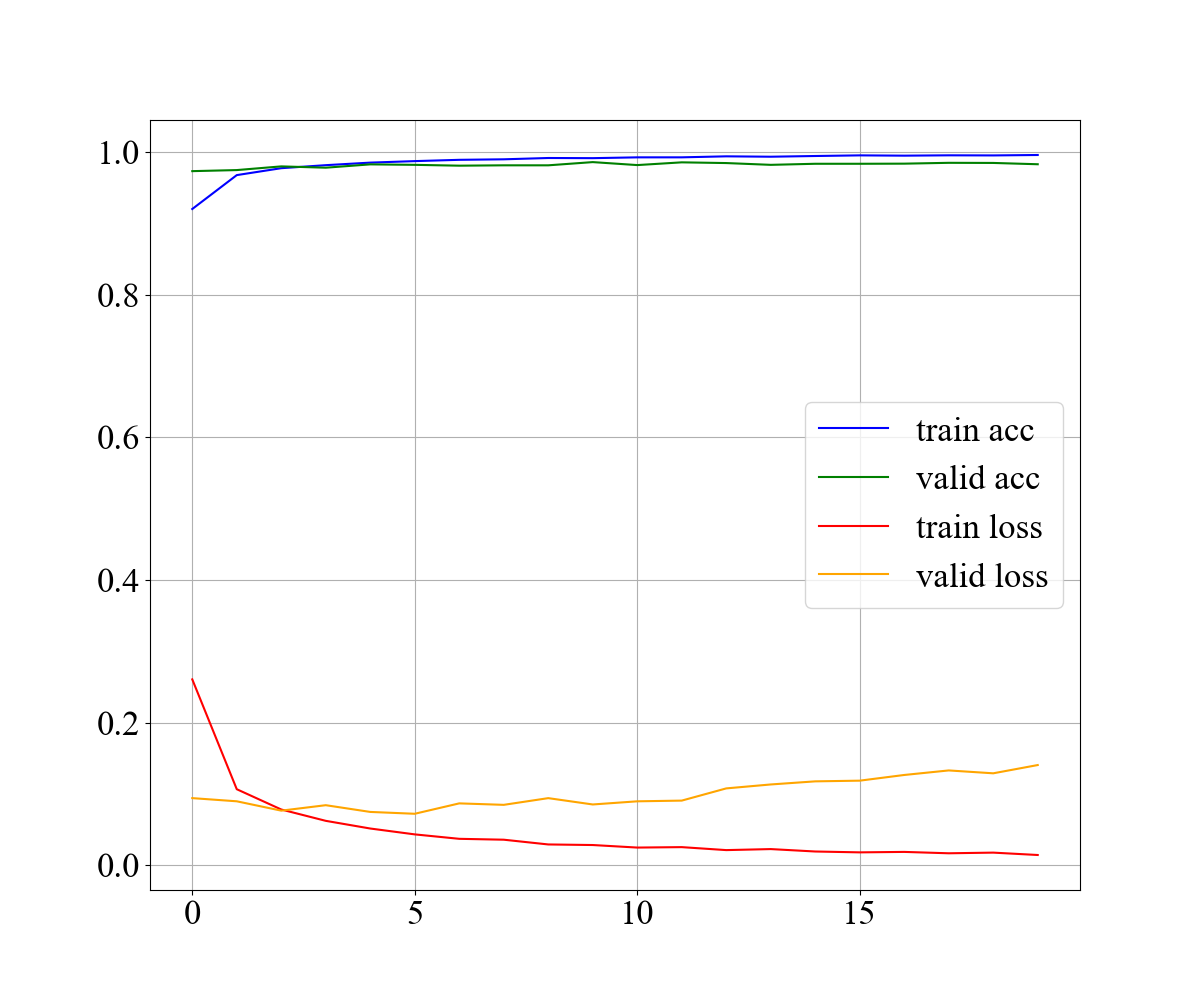
accuracy
accuracy(正答率)を見てやると、学習用データの結果(accuracy train)、検証用データの結果(accuracy valid)ともに精度が右肩上がりです。また、acc < val_accとなっていないので、学習は十分であるともみれます。
loss
loss(損失値・誤差)は、検証データ(loss valid)が5エポック目以降から上がっていき、精度が下がっているのがわかります。
学習用データ(loss train)のほうは右肩下がりなので過学習が発生している可能性があります。
| – | loss(training) 小さい | loss(training) 大きい |
|---|---|---|
| loss(valid) 小さい | 良い学習 | コードエラー |
| loss(valid) 大きい | 過学習 | 未学習 |
【補足】過学習とは
過学習とは、同じようなデータを使って学習し続けると、そのデータだけに強いモデルとなり、本番データに対する認識率が逆に下がってしまう減少です。
受験生で例えると、「ある特定の過去問ばかりを勉強した結果、過去問と傾向が異なる未知の問題が出てきたときに全く点がとれなくなる」ことです。
そのため学習する際は、評価データで精度向上度合いを確認し、ある程度飽和したところで学習を終了することが必要になります。
そのため、作成したモデルの精度は、学習に用いたデータではなく、未知のテストデータで測定してやる必要があります。
未知のデータに対する誤りを「汎化誤差」といい、汎化誤差が小さいことを「汎化能力が高い」といいます。
過学習を防ぐ方法としては、データセットを増やしたり、正則化を行うことが多いです。
| – | – |
|---|---|
| 正則化 | データの複雑さに対してペナルティを設け、このペナルティを訓練誤差に加えた量が最も小さくなる学習モデルを求めることで汎化性能を高めます。代表例としてL1正則化(特定のデータの重みを0にし、不要なデータを削除)、L2正則化(データの大きさに応じて値を0に近づけて滑らかにする)があります。 |
| データセットを増やす | データセットを増やすのは大変なので、学習用データに対して人工的なノイズなどを付加した画像を新たに生成し、データセットに追加することで水増しする方法などがあります。 |


コメント